
1995년부터 현재까지 모든 종목들의 가격데이터를 한 테이블에 욱여넣었는데 종목별로 하나씩 DataFrame을 생성한 후에 수정주가를 일괄적으로 계산하려고 하는데 예상치 못한 난관에 처했다. 과거 시점에 상장폐지 되거나 코드가 바뀐 것들까지 다 포함하면 4863개의 종목코드가 존재하는데 테이블 크기가 워낙 크다 보니 극악의 퍼포먼스가 나왔다.
처음엔 아래와 같이 sql로 종목코드를 지정해서 하나씩 데이터를 가져오려고 했는데 너무 시간이 많이 소요됐다. 어쩔 수 없이 전체 테이블을 한꺼번에 가져와서 DataFrame을 종목코드로 필터를 건 후에 하나씩 처리해 보기로 했다.
query = f"SELECT * FROM stock WHERE code == '{code}'"
df = pd.read_sql(query, con)
1. Pandas Filter
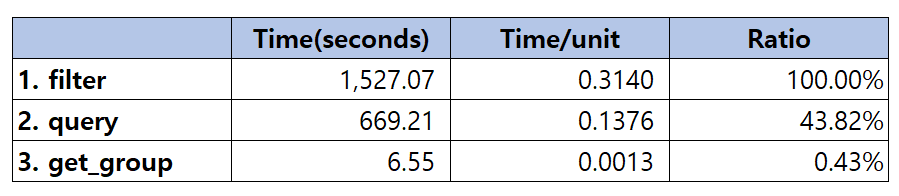
가장 우선적으로 Pandas의 필터를 활용해 봤는데 개당 처리 속도가 약 0.3초가량 나왔다. 4863개를 모두 처리하는데 25분이 넘게 걸렸다. sql로 하나씩 접근하는 것보다는 빨랐지만 충분하지 않았다.
total_dict = {}
for code in code_list:
total_dict[code] = total_df[total_df['code'] == code]
2. Pandas.query
다른 방법이 있을 것 같아서 구글링을 하다가 찾은 Pandas.DataFrame.query를 사용해 보기로 했다. 4863개의 종목코드를 처리하는 데 걸린 전체 시간은 11분가량으로 개당 처리 속도는 약 0.13초로 엄청나게 단축되었다.
total_dict = {}
for code in code_list:
total_dict[code] = total_df.query(f"code == '{code}'")
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
pandas.DataFrame.query — pandas 1.5.3 documentation
The query string to evaluate. You can refer to variables in the environment by prefixing them with an ‘@’ character like @a + b. You can refer to column names that are not valid Python variable names by surrounding them in backticks. Thus, column names
pandas.pydata.org
3. Pandas.core.groupby.GroupBy.get_group
전체 처리 속도가 초단위로 나오지 않는다면 안된다고 생각해서 다시 열심히 구글링을 하다가 찾은 방법인데 groupby를 적용해 놓고 다시 하나씩 데이터를 끄집어내는 방법을 찾았다. 아래 코드와 같이 code로 groupby를 하고 get_group을 사용해서 하나씩 데이터를 가져오면 된다.
그 결과, 전체 소요시간은 6초대로 말도 안 되게 빨라졌다.
data_grp = total_df.groupby('code')
total_dict = {}
for code in code_list:
total_dict[code] = data_grp.get_group(code)
위의 세 가지 방법들로 테스트해 본 결과는 아래와 같다.
[전체 코드 및 실행결과]
import pandas as pd
from datetime import *
import connectorx as cx
import urllib
def read_sql_using_connectorx():
DB_PATH = 'database_krx_marcap.db'
database_path = urllib.parse.quote(DB_PATH)
query = f"SELECT * FROM stock"
con = 'sqlite://' + database_path
df = cx.read_sql(con, query)
return df
def df_filter(total_df, code_list):
start_time = datetime.now()
total_dict = {}
for code in code_list:
total_dict[code] = total_df[total_df['code'] == code]
print('df_filter', datetime.now() - start_time)
return total_dict
def df_query(total_df, code_list):
start_time = datetime.now()
total_dict = {}
for code in code_list:
total_dict[code] = total_df.query(f"code == '{code}'")
print('df_query', datetime.now() - start_time)
return total_dict
def data_grp(total_df, code_list):
start_time = datetime.now()
data_grp = total_df.groupby('code')
total_dict = {}
for code in code_list:
total_dict[code] = data_grp.get_group(code)
print('data_grp', datetime.now() - start_time)
return total_dict
total_df = read_sql_using_connectorx()
print(total_df)
print(total_df.info())
code_list = total_df['code'].unique()
print(code_list)
print(len(code_list))
df_filter(total_df, code_list)
df_query(total_df, code_list)
data_grp(total_df, code_list)
'Python, API' 카테고리의 다른 글
| Numba 0.57 Release (Support for Python 3.11) (0) | 2023.05.03 |
|---|---|
| [Python/키움API] 주식 틱차트 조회요청 (OPT10079) 및 저장 (2) | 2023.04.24 |
| [Python] KRX 주가데이터로 수정주가 계산 (0) | 2023.03.25 |
| Pandas.read_sql 속도 비교 (chunksize, connectorx) (0) | 2023.02.26 |
| [Telegram API] pyTelegramBotAPI로 메시지 보내기 (0) | 2023.02.08 |


